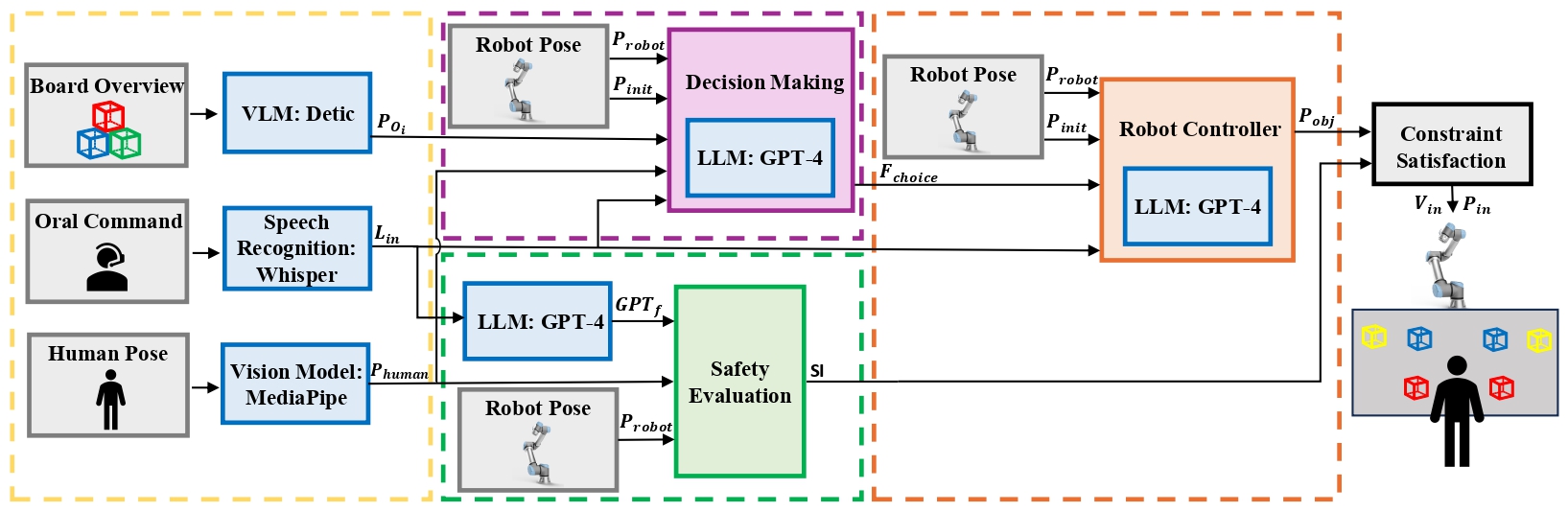
As robots increasingly integrate into the workplace, Human-Robot Collaboration (HRC) has become increasingly important. However, most HRC solutions are based on pre-programmed tasks and use fixed safety parameters, which keeps humans out of the loop. To overcome this, HRC solutions that can easily adapt to human preferences during the operation as well as their safety precautions considering the familiarity with robots are necessary. In this paper, we introduce GPTAlly, a novel safety-oriented system for HRC that leverages the emerging capabilities of Large Language Models (LLMs). GPTAlly uses LLMs to 1) infer users' subjective safety perceptions to modify the parameters of a Safety Index algorithm; 2) decide on subsequent actions when the robot stops to prevent unwanted collisions; and 3) re-shape the robot arm trajectories based on user instructions. We subjectively evaluate the robot's behavior by comparing the safety perception of GPT-4 to the participants. We also evaluate the accuracy of natural language-based robot programming of decision-making requests. The results show that GPTAlly infers safety perception similarly to humans, and achieves an average of 80% of accuracy in decision-making, with few instances under 50%.
The first goal is to demonstrate the capacity of LLMs to estimate human safety perceptions through a scaling factor (GPT
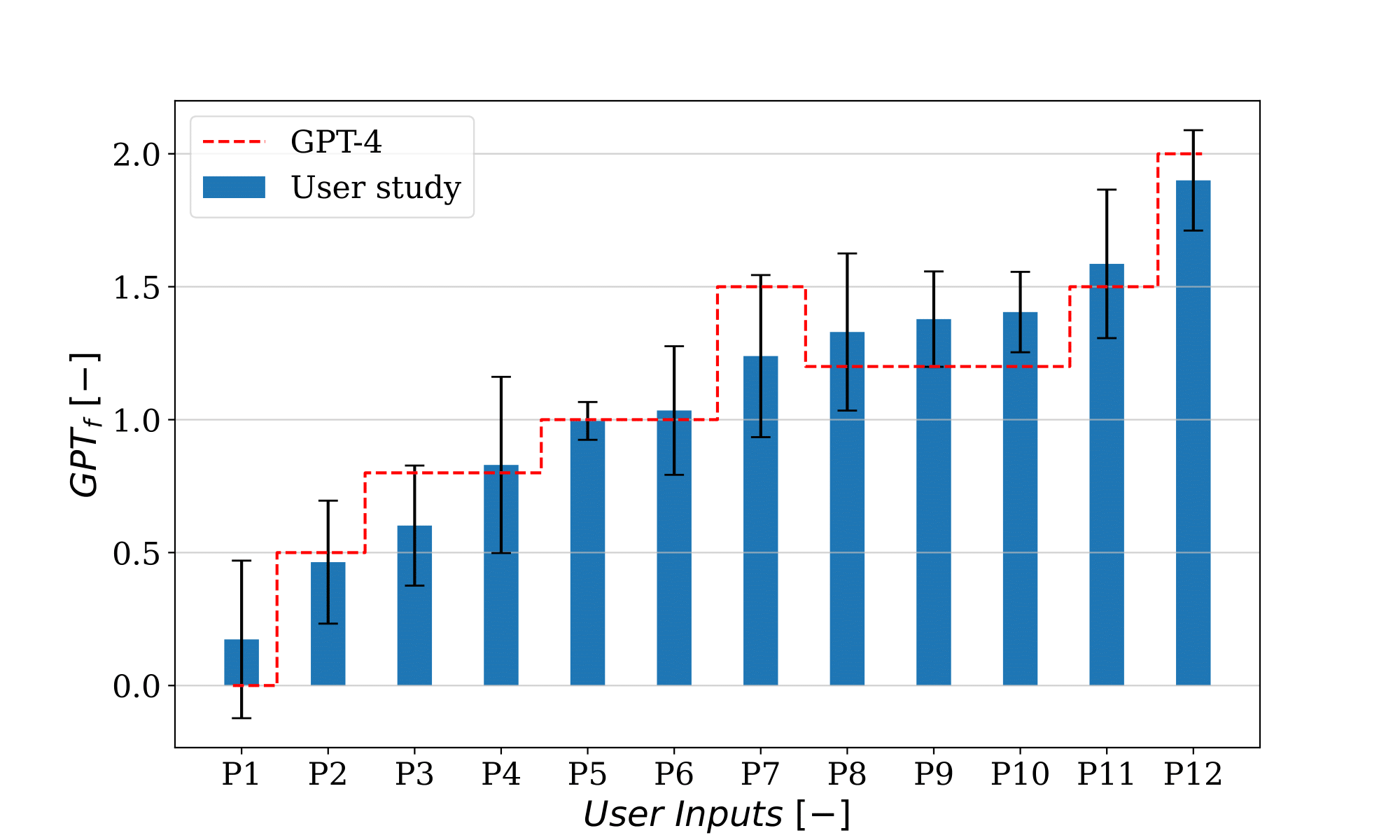
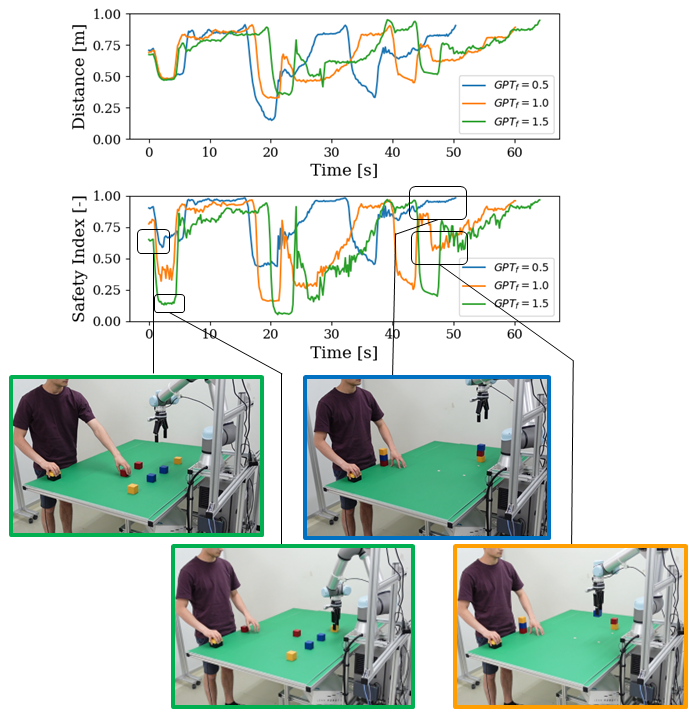
Through the experiment detailed here, the next goal is to demonstrate how LLMs can integrate human perception of safety into safety assessments. This is achieved by analyzing the reaction and efficiency of the robot with different GPT

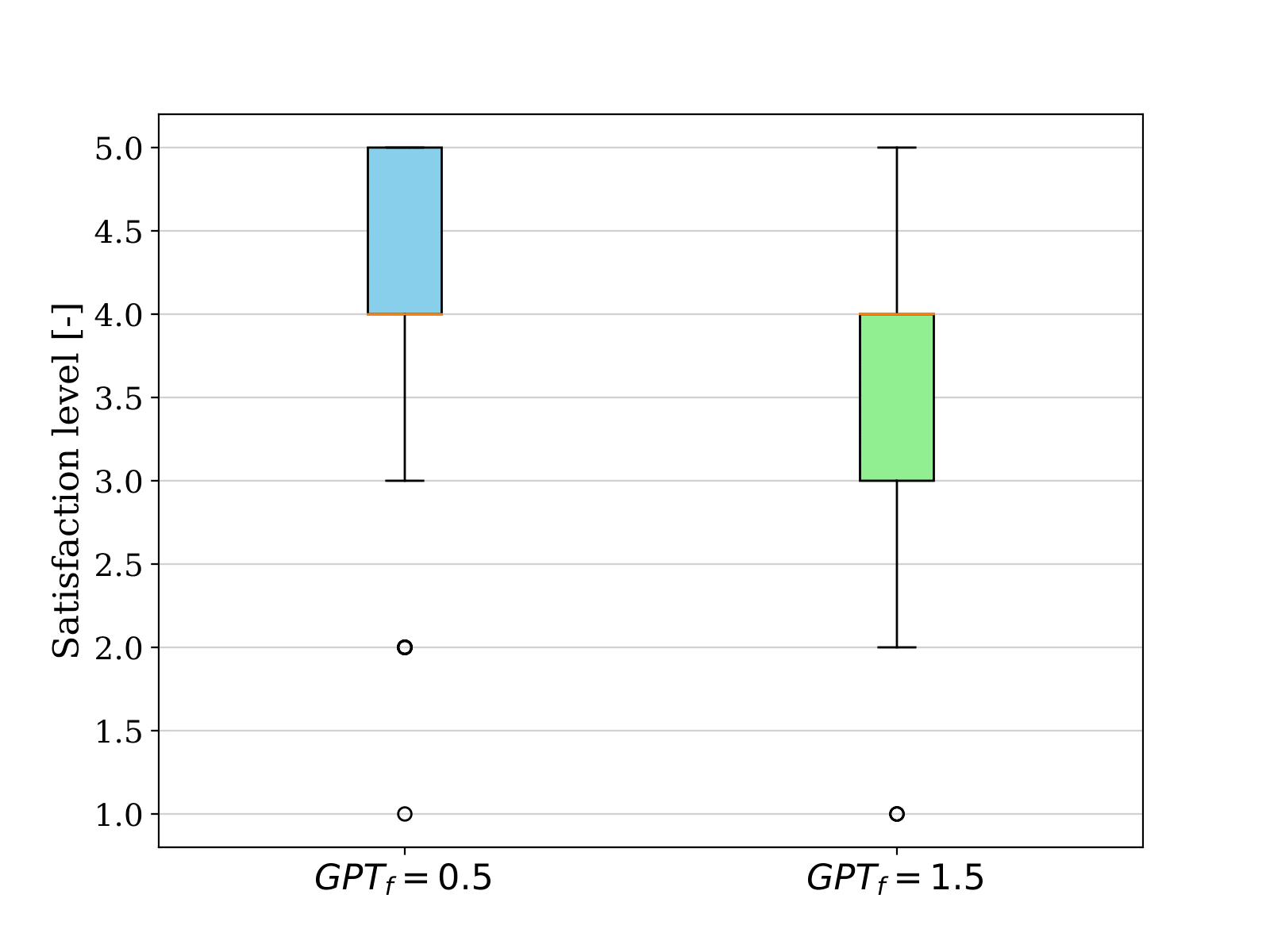
In the following qualitative assessment, the satisfaction of the user with the behavior of the robot with different input prompts is tested through a user study. They are requested to assess their level of satisfaction on a scale of 1 to 5 (1 is very unsatisfied and 5 is very satisfied) regarding the new behavior of the robot in comparison to its neutral behavior (where GPT
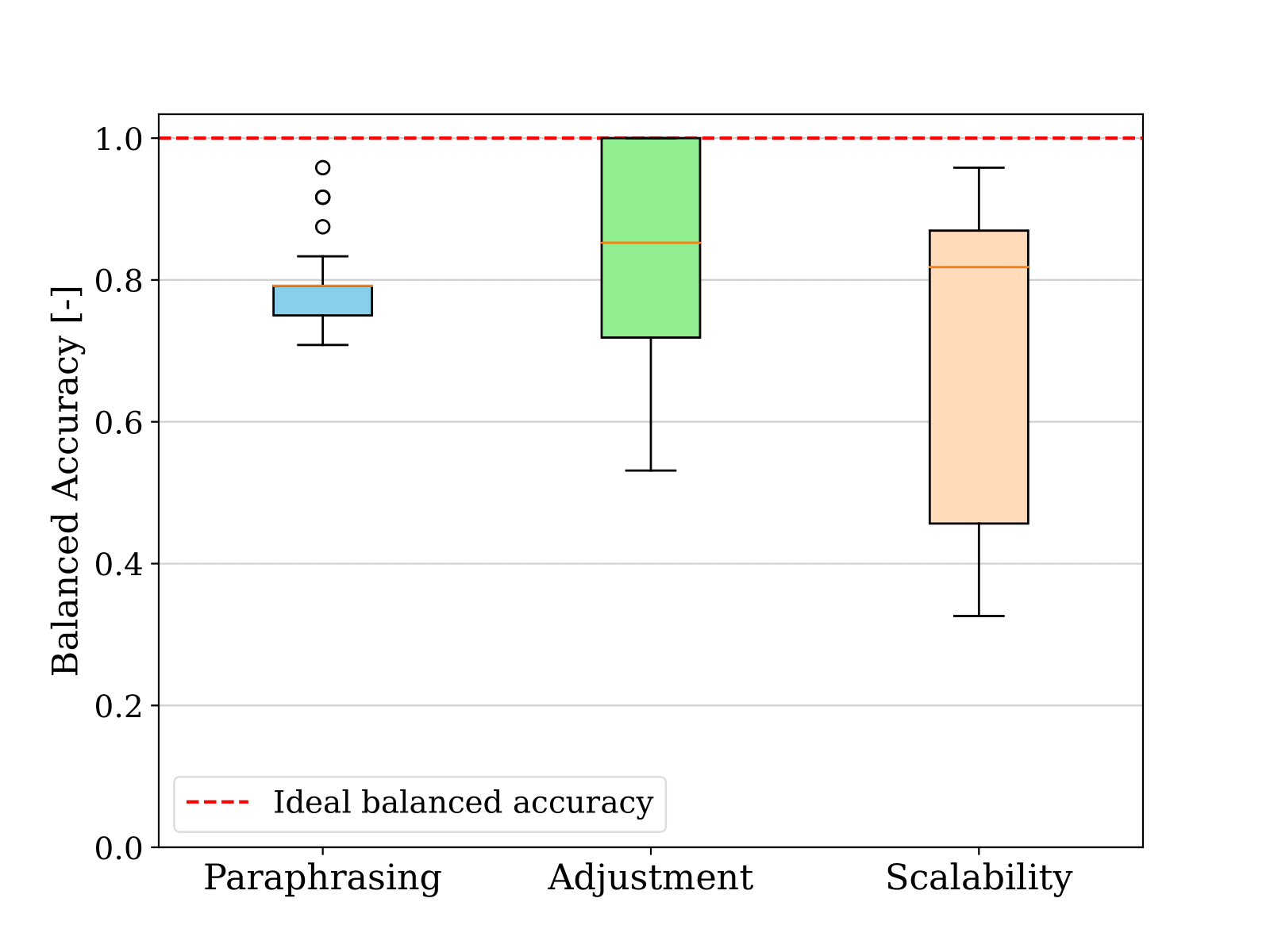
Three distinct tests are made to evaluate the viability of using LLMs as a streamlined coding paradigm. The first one consists of changing the natural language used to express the same condition on the input and thereby assessing the condition paraphrasing. Then, with language inputs that follow a similar structure, namely condition adjustment, different conditions are tested. The final step is to assess the scalability of the condition (condition scalability), gauging the system's capability to effectively manage increasingly intricate conditions. An extensive description of the experiment can be found here.
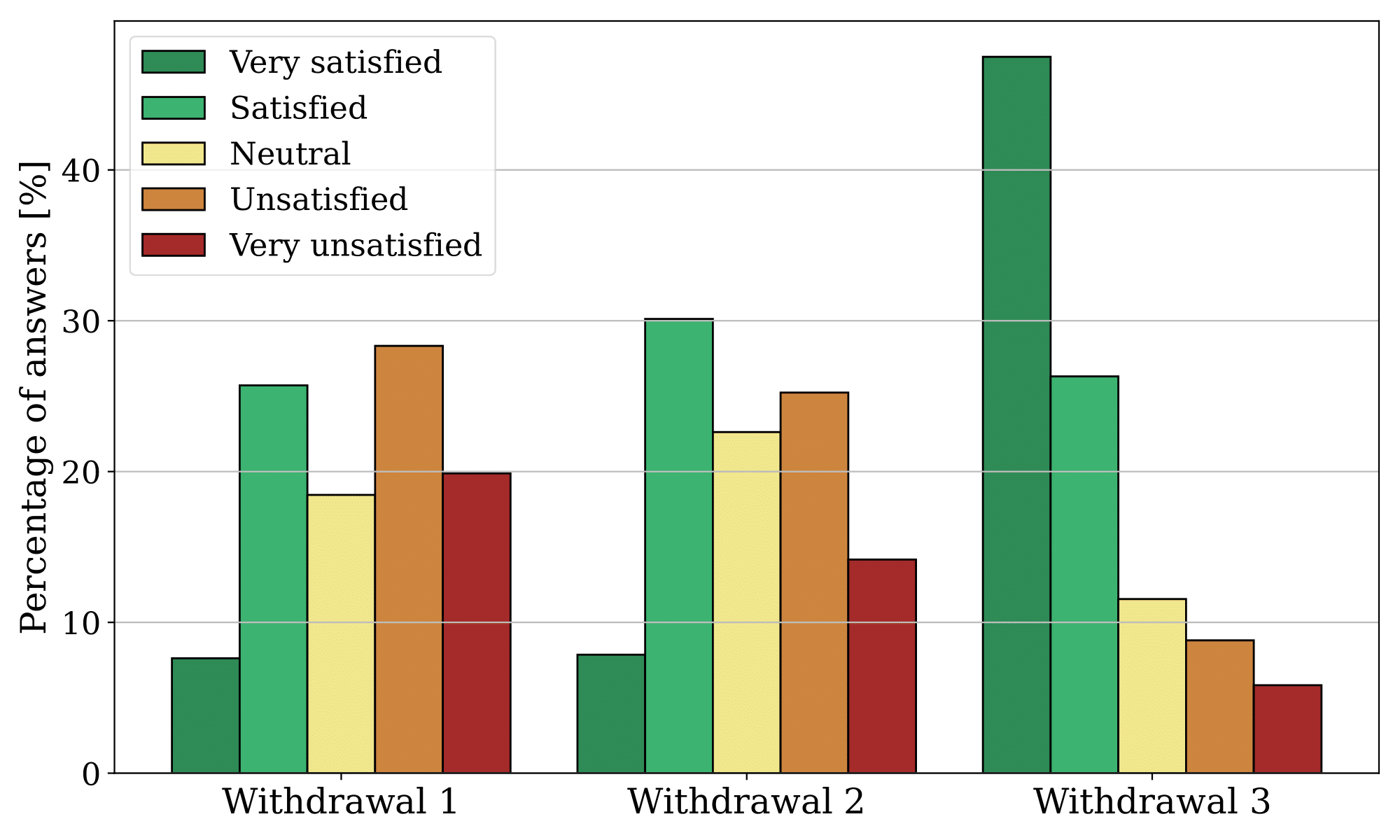
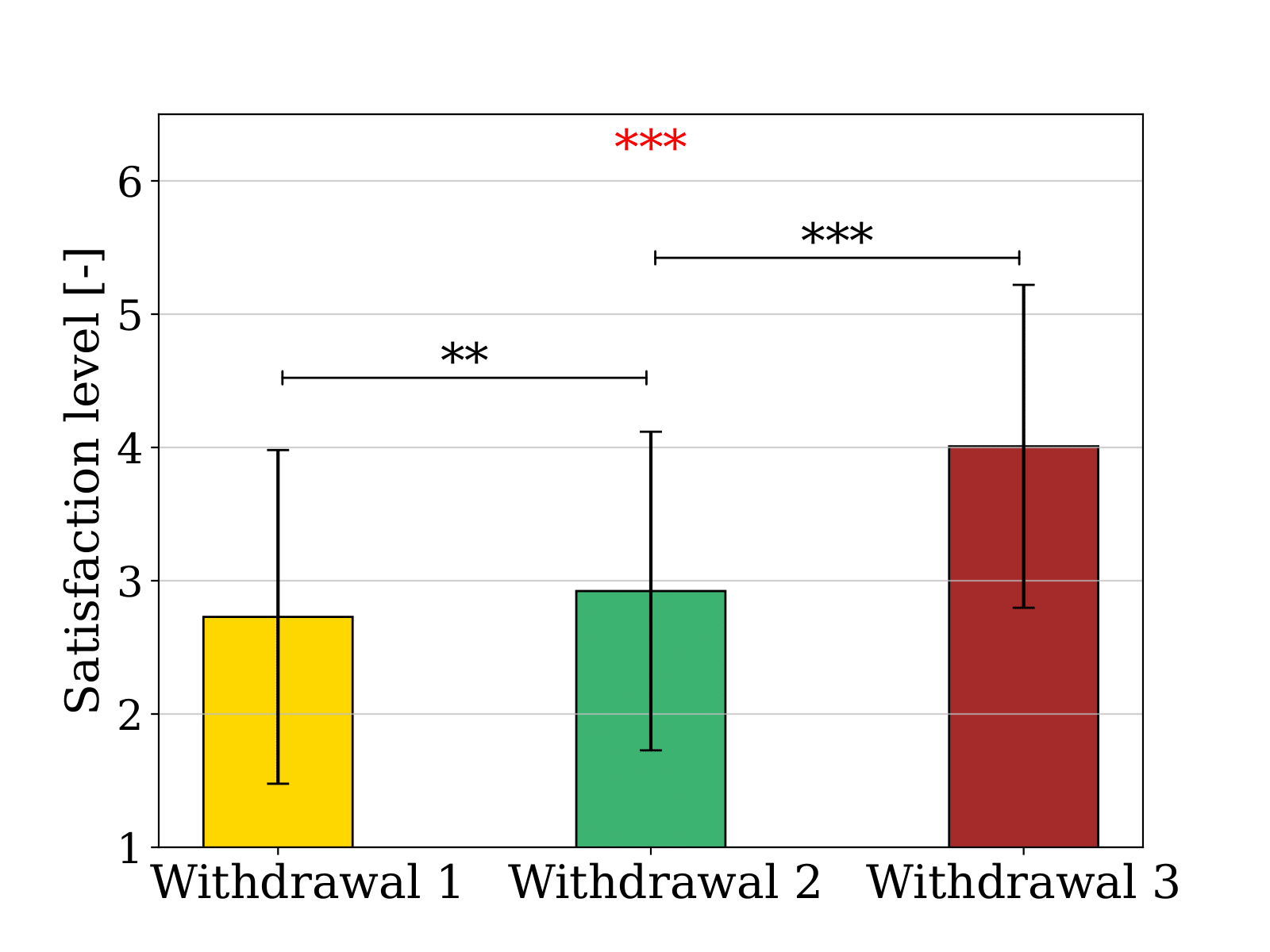
The objective of this experiment is to evaluate the use of LLMs to shape robotic arm trajectories. The methods' performance was evaluated through a user study, where a total of 150 data points were collected from each of the 30 participants. Each participant was asked to rate the withdrawal methods on a 1-5 Likert scale, based on a given natural language input. The following figure summarizes the distribution of the answers for each method. Withdrawal 1 represents the withdrawal method proposed by Garcia et al., Withdrawal 2 is the same method with the parking position modified by GPT-4, and Withdrawal 3 is the method where GPT-4 suggests a new withdrawal position directly.
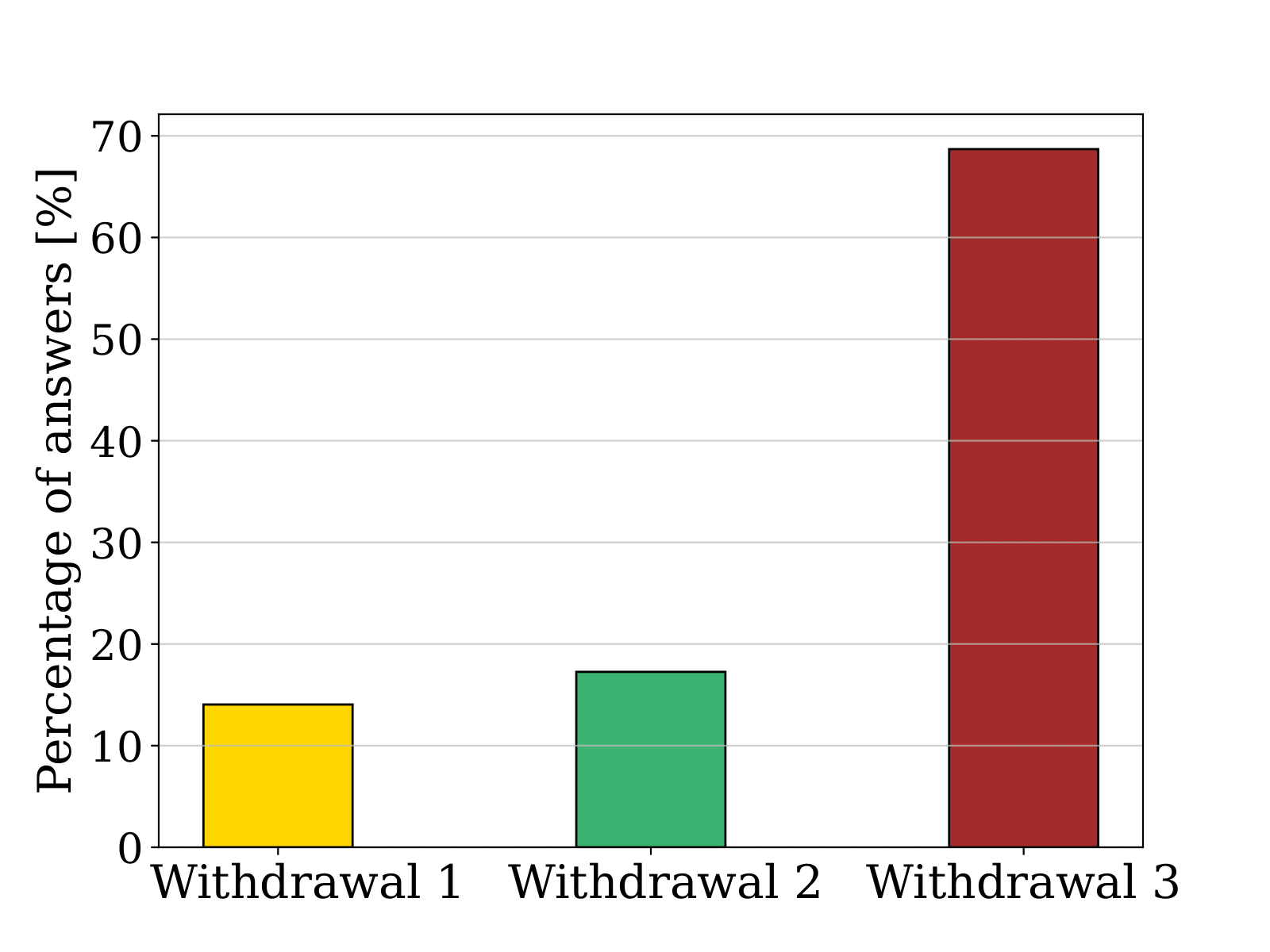
In the same user study, participants were asked to select their preferred withdrawal method if they were in the user's situation. On the left, the figure displays the average satisfaction level, ranging from 1 (very unsatisfied) to 5 (very satisfied). A Kruskal–Wallis test and two Mann–Whitney U tests were conducted to examine the differences between the means. In the same user study, participants were asked to select their favorite withdrawal method if they were in the user's situation, as shown on the right. Unlike the previous question where they had to assess their satisfaction, they were asked to decide on only one favorite.
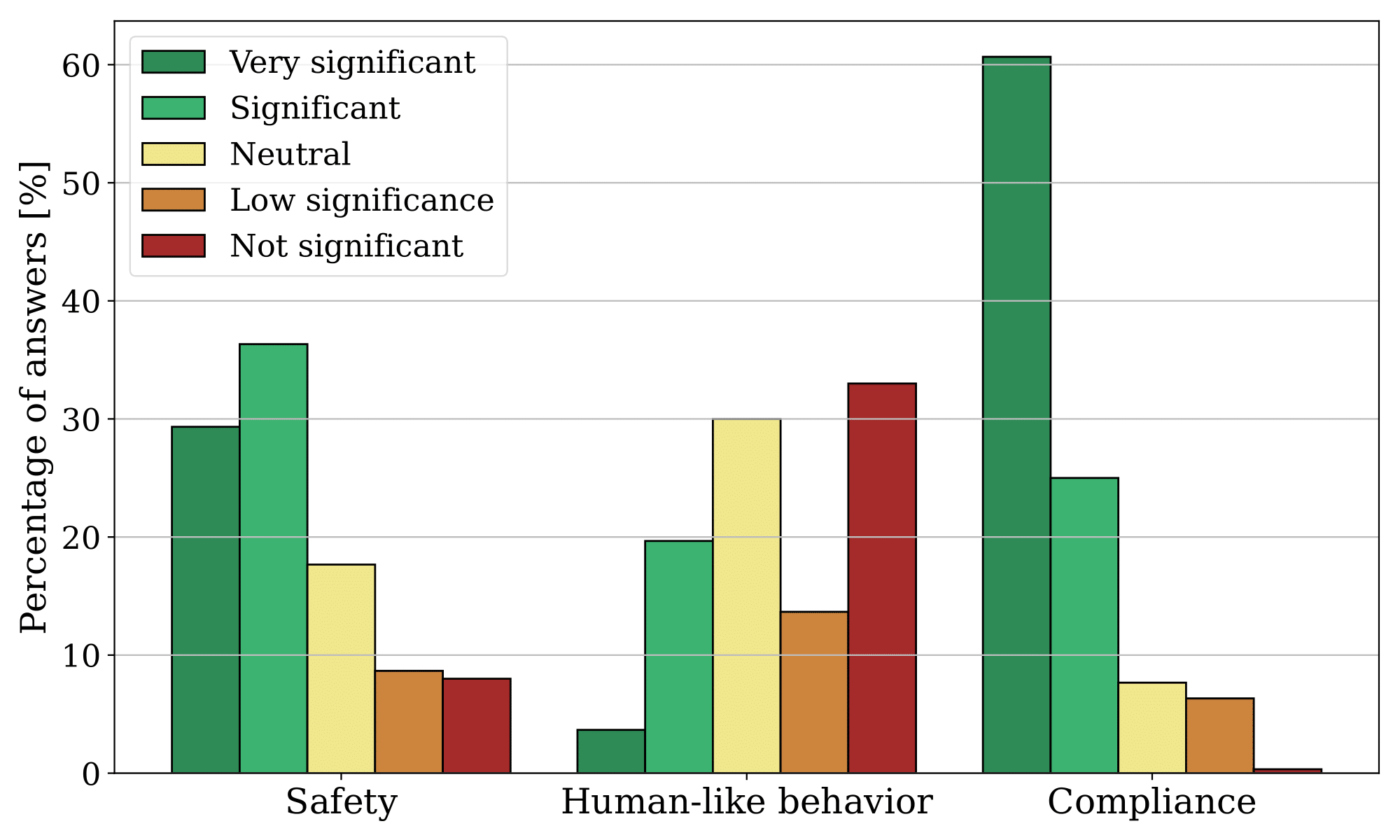
The users were also asked to assess the significance of each factor for their previous answers. The following figure displays the distribution of their responses. There were three factors they had to evaluate: safety, which refers to the robot moving to a safer location; compliance, which indicates the robot following the user's command; and human-like behavior, which involves the robot exhibiting behavior resembling that of a human.
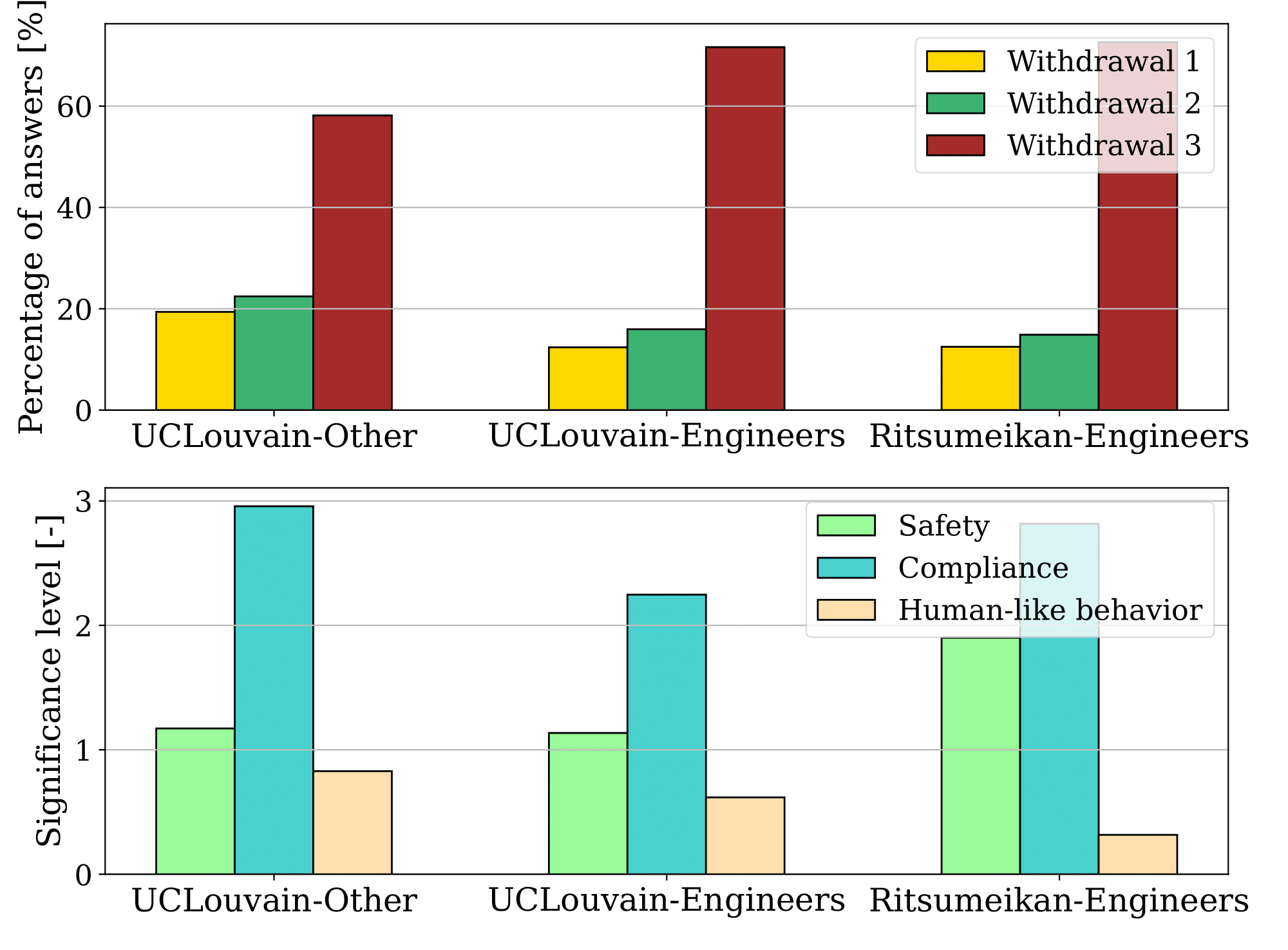
Finally, the distributions from the users were divided into three groups: students from UCLouvain who did not receive an engineering education (UCLouvain-Other), students from UCLouvain who did receive an engineering education (UCLouvain-Engineer), and students from Ritsumeikan who received engineering education (Ritsumeikan-Engineer). UCLouvain students study in Belgium, while Ritsumeikan students study in Japan.
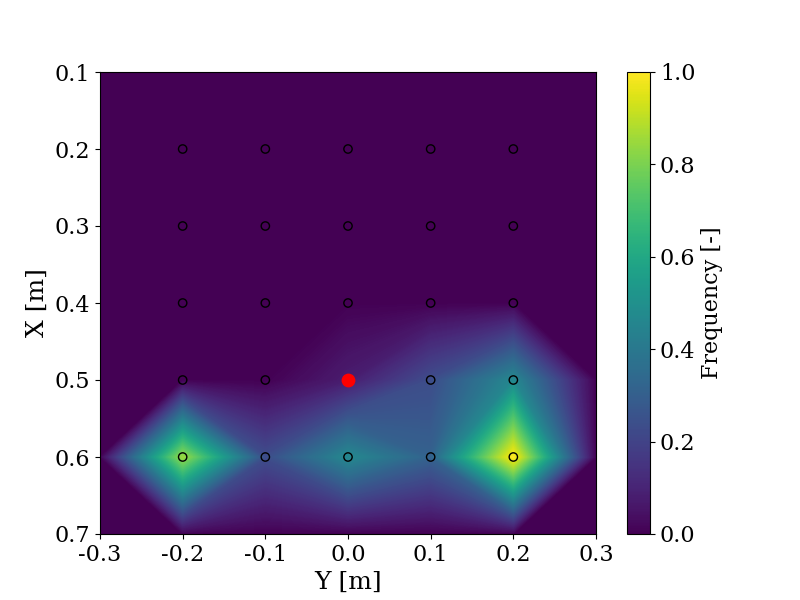
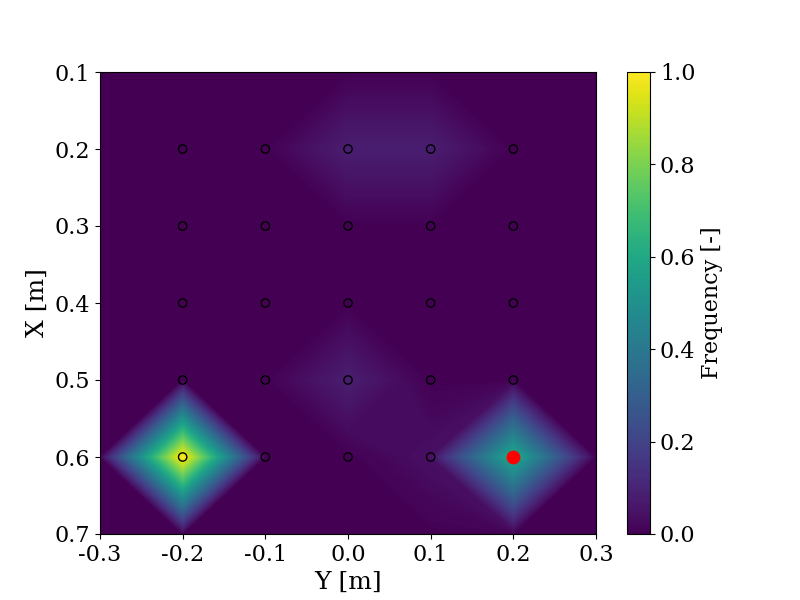
With the same objective of evaluating the use of LLMs to shape trajectories, the change in objective is evaluated by comparing the responses provided by GPT-4 and users in a user study when given the same instructions, such as "Pick a block between me and the robot". The user ("Me") is positioned in (0.7, 0.0) and the robot is positioned in (0.1, 0.0). In red is the answer from GPT-4 and the frequency indicates the number of times a user chose this block relative to the maximum number of times any block was chosen. The experiment is explained more in detail here.
On the left side, the prompt provided to both the user and GPT-4 is "Take a block that is close to me". On the right side, the prompt is "Take a block that is close to the robot".
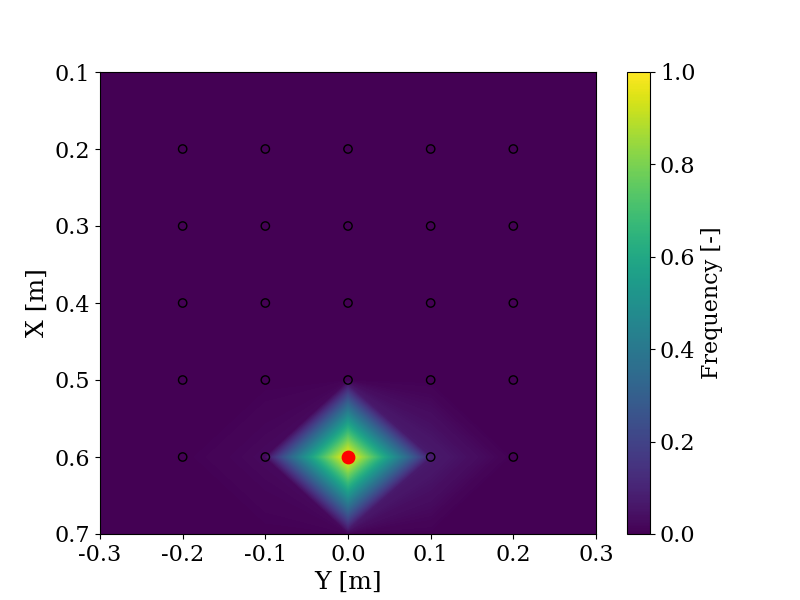
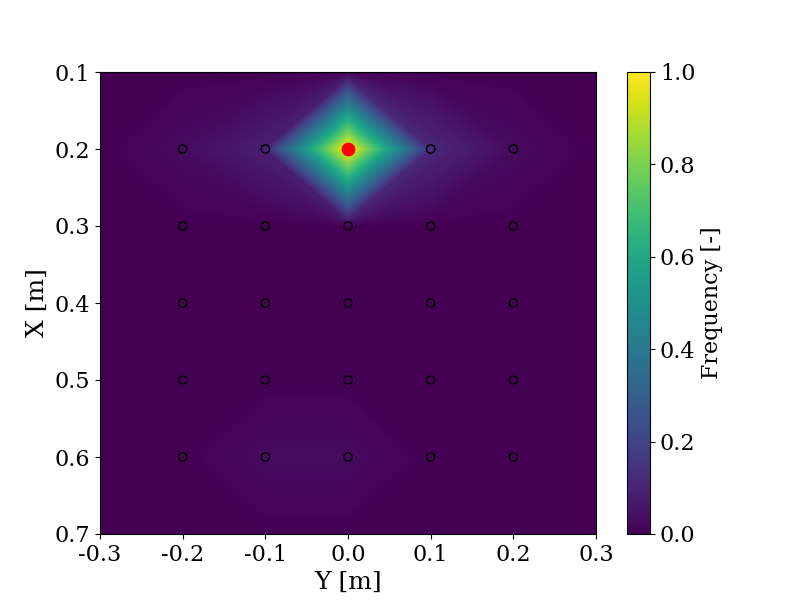
On the left side, the prompt is "Take a block on the left", and on the right side, the prompt is "Take a cube on the right".
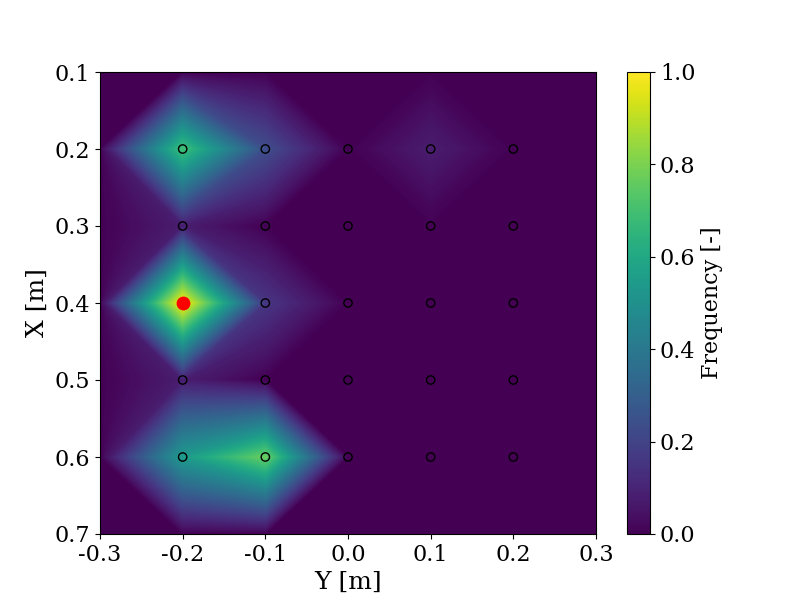
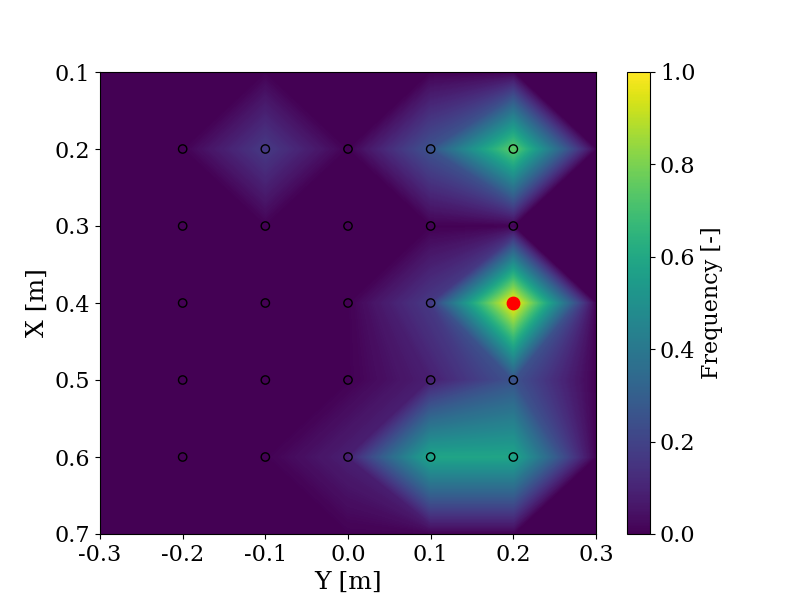
On the left side, the prompt is "Take a block far from the robot", and on the right side, the prompt is "Take one of the furthest block from the robot".